 - Link to source")
Just sayin'...

Don't take this as any sort of science. Then again, you don't need much science to ascertain line go up. And up it goes. Forecasting was done with Prophet. Data is all the model scores I could find for ARC-AGI 1 & 2, plus HLE.
And honestly, I don't think we'll have to wait until November 2026 for HLE to saturate as well, but now I'm just guessing... Right? Right...?
Google is taking complete control over app distribution on Android
Starting next year, Google is planning to acquire complete control over app installation on all Android devices. They'll do this by introducing mandatory "developer verification", where every Android app must be signed by a developer key that is whitelisted by Google.
Getting whitelisted will require handing over government ID documents and paying Google for this privilege.
This is of course being marketed as the usual "keeping users safe" nonsense. The reality is that Google will now be able to remotely disable any app on any device, for whatever reason.
I am sure I don't have to elaborate on the quite horrible implications this has.
If you are at all concerned about something like this, please act now. There is still a slight chance that we can overturn this, but if they succeed, it will be an unrecoverable blow to free and open communication and compute.
To see how you can help prevent this, go to:
Keep Android Open
Advocating for Android as a free, open platform for everyone to build apps on.Keep Android Open

RNS 1.0.4 Released
This maintenance release adds improved handling for RNodes with a PA/LNA combo.
Changes
- Improved handling for RNodes with PA/LNA combo
- Added interference detection stats to rnstatus output for RNode interfaces
- Updated documentation
Release Hashes
7a2b7893410833b42c0fa7f9a9e3369cebb085cdd26bd83f3031fa6c1051653c rns-1.0.4-py3-none-any.whl
ee647e7b3b94abdf1fab618a861390531a4aacc93eecce12c9e97280195c0e2d rnspure-1.0.4-py3-none-any.whlGet this #release via pip or GitHub.

Release RNS 1.0.4 · markqvist/Reticulum
This maintenance release adds improved handling for RNodes with a PA/LNA combo. Changes Improved handling for RNodes with PA/LNA combo Added interference detection stats to rnstatus output for RNo...GitHub
Mark Qvist likes this.
Mark Qvist reshared this.
RNS β 0.9.5 Released
This release initiates migration of Reticulum from AES-128 to AES-256 as the default link and packet cipher mode. It is a compatibility/migration release, that while supporting AES-256 doesn't use it by default. It will work with both the old AES-128 based modes, and the new AES-256 based modes. There's a very slight penalty in performance to support both the old and new modes at the same time, but only for single packet APIs (not links), and it really shouldn't be noticeable in any everyday use.
In the next release, version 0.9.6, Reticulum will transition fully to AES-256 and use it by default for all communications. That means that both single packets and links will use AES-256 by default. The old AES-128 link mode may or may not be available for a few releases, but will ultimately be phased out entirely.
The update requires no intervention, configuration changes or anything similar from a users or developers perspective. Everything should simply work. This goes both for the 0.9.5 update, and the next 0.9.6 update that transitions fully to AES-256.
Changes
- Added support for AES-256 mode to links and packets
- Added dynamic link mode support
- Added temporary backwards compatibility for AES-128 link and packet modes
- Added get_mode() method to link API
- Added tests for all enabled link modes
- Added instance_name option and description to default config file
- Improved ratchet persist reliability if Reticulum is force killed while persisting ratchets
- Fixed interface string representation for some interfaces
- Fixed instance name config option being overwritten if option was not last in section
- Fixed unhandled potential exception on fast-flapping BackboneInterface connections
Release Hashes
ae6587c86c98cae0df73567af093cc92fe204e71bb01f2506da9aec626a27e97 rns-0.9.5-py3-none-any.whl
96208c1d1234e3e4b1c18ca986bad5d4693aeb431453efd7ade33b87f35600e1 rnspure-0.9.5-py3-none-any.whlGet this #release via pip or GitHub.

Release RNS β 0.9.5 · markqvist/Reticulum
This release initiates migration of Reticulum from AES-128 to AES-256 as the default link and packet cipher mode. It is a compatibility/migration release, that while supporting AES-256 doesn't use ...GitHub
Mark Qvist likes this.
reshared this
We're now in the final stretch of the beta phase of #Reticulum. There's quite a bit to share, so I've just posted an update over on my site unsigned.io, rather than re-iterating it all in this post, you can read it in full here:


Radio Settings | Meshtastic
Maximize your Meshtastic device's potential with detailed radio settings instructions, including frequency bands, data rates, and encryption options.meshtastic.org
Mark Qvist likes this.
Mark Qvist reshared this.
The master does it again: Kaleidoscopico
")
Kaleidoscopico (A Demo for the Raspberry Pi Pico 2)
2nd place in the Wild compo at Revision 2025. Yay!I haven't finished the technical writeup yet, but wanted to get this uploaded while it's still hot. I'll up...YouTube
RNS β 0.9.4 Released
This release significantly improves memory utilisation and performance. It also includes a few new features and general improvements to the included utilities and programs.
Changes
- Significantly improved memory utilisation, thread count and performance on nodes with many interfaces or clients
- Switched local instance communication to run over abstract domain sockets on Linux and Android
- Switched instance IPC to run over abstract domain sockets on Linux and Android
- Added kernel event based I/O backend on Linux and Android
- Added fast BackboneInterface type
- Added support for XIAO-ESP32S3 to rnodeconf
- Added interactive shell option to rnsd
- Added API option to search for identity by identity hash
- Added option to run TCP and Backbone interfaces in AP mode
- Improved RNodeMultiInterface host communications specification
- Improved rncp statistics output
- Improved link and reverse-table culling
- Fixed an occasional I/O thread hang on instance shutdown, that would result in an error printed to the console
- Fixed various minor interface logging inconsistencies
- Fixed various minor interface checking inconsistencies
- Updated internal configobj implementation
- Refactored various parts of the transport core code
- Swicthed to using internal netinfo implementation instead of including full ifaddr library
- Cleaned out unneeded dependencies
Release Hashes
4b01260519d0c995f343ad325c302b779557fa686ec81bf00161696f0d657689 rns-0.9.4-py3-none-any.whl
c590be37c813f5c145649fcf488a4fdd1687b6187ab02a8679ca730c511fb042 rnspure-0.9.4-py3-none-any.whlGet this #release via pip or GitHub.

Release 0.9.4 · markqvist/Reticulum
RNS β 0.9.4 This release significantly improves memory utilisation and performance. It also includes a few new features and general improvements to the included utilities and programs. Changes Sig...GitHub
reshared this
Throughput Up, Resource Use Down
The upcoming 0.9.4 release of Reticulum will include a series of significant improvements to system resource utilization. Work has been focused on the core I/O handling and internal in-memory data structures. This has resulted in substantial reductions in both memory consumption, thread counts and CPU utilization, especially noticeable on nodes with many interfaces or connected clients.
Lighter Memory Footprint
The in-memory table structures have been optimized significantly, and disk caching added for data that doesn't need to stay loaded in resident memory. Memory cleanup, path table management and table entry purging has also been overhauled and optimized.
The net result is a reduction in resident memory load of approximately 66%. As an example, one testnet node with 270 interfaces and around 800 concurrently active links incurred a memory load of 710 MB on rnsd version 0.9.3.
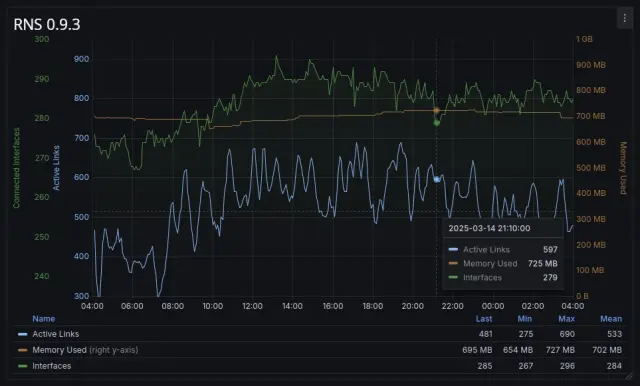
With the new optimizations in 0.9.4, memory load stabilizes at a much lighter 230 MB under similar conditions.
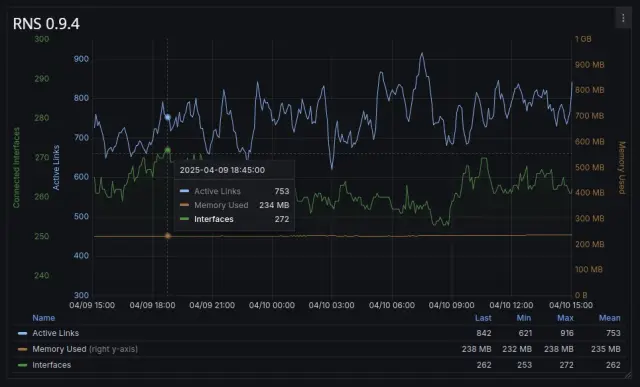
These improvements are of course going to be most noticeable on well-connected transport nodes, but even for small or singular application-launched instances, the improvements are important, and contribute to the goal of running even complex RNS applications on very limited hardware.
Faster I/O Backend
A new backend for handling interface I/O, and shipping packets off to the RNS transport core, has also been added in this upcoming release. It uses kernel-event based I/O polling, instead of threads for reading and writing the underlying hardware (or virtual) devices. This approach is *much* faster, and of course decreases processing time wasted in multi-threading context switches significantly.
On RNS `0.9.3`, the example node from before utilized around 275 threads, but on version `0.9.4`, everything is handled by a mere *6 threads*, grand total. That includes *all* the threads of RNS, like those needed for running memory maintenance, managing storage and caching, and other backend handling.
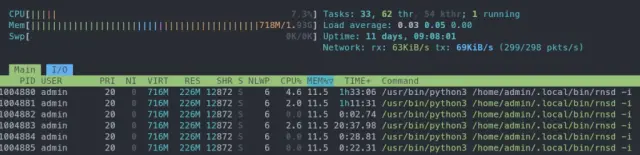
Additionally, the new I/O backend uses abstract domain sockets for communication between different RNS applications on the same system, offering a slight, but still welcome performance improvement. More importantly, though, using domain sockets for intra-RNS instance communications makes it *much* easier to handle several different RNS instances running on the same system, as these can now simply be given human-readable namespaces, making config file management and complex setups a lot more manageable.
To run several isolated RNS instances on the same system, simply set the `instance_name` parameter in your RNS config files. You can verify that your instance is indeed running under the correct namespace (here the default system namespace) by using the rnstatus command, which should give you output such as the following:
Shared Instance[rns/system]
Status : Up
Serving : 3 programs
Rate : 1.00 Gbps
Traffic : ↑8.61 GB 798.45 Kbps
↓11.51 GB 859.64 KbpsIn this initial release, the new I/O backend is available on Linux and Android. The plan is to extend it to Windows and macOS in future releases, but since these operating systems have different ways of interacting with kernel event queues, it makes sense to stage the deployment a bit, and make sure that everything is working correctly before adding support for these as well.
Lower CPU Load
The improvements to memory structure, increased I/O efficiency and decreased thread counts all contribute to lowering the CPU load required to run Reticulum. Especially the much decreased need for context switching makes a positive difference here, and this is very noticeable on systems that handle very large numbers of interfaces or connected clients.
The testnet node referred to in this post is a small single-core VM, that handles between 250 to 320 interfaces, and between 700 to 1,000 active links at any given time. Even on such a small machine, CPU usage rarely spikes above 15%, and long-time load average is essentially always at `0.01`.
While there is still many more options to work on, for even better performance and lower resource utilization, this work is a big step forwards in terms of immediately useful scalability, and the ability to deploy even large and complex Reticulum-based systems and applications on very modest hardware, such as low-power SBCs and embedded devices.
Mark Qvist likes this.
reshared this
Cultural Diversion
We have to stop consuming our culture. We have to create culture. Don't watch TV, don't read magazines, don't even listen to NPR. Create your own roadshow. You want to reclaim your mind, and get it out of the hands of the cultural engineers, who want to turn you into a half-baked moron consuming all this trash, that's being manufactured out of the bones of a dying world.
- Terence McKenna
Back in 2008, I recorded this track with an old guitar, a Korg Kaoss Pad and a very cheap midi keyboard. It's been hanging out in my drawer for 17 years, but now it's available here. McKenna's words are as relevant today as ever.
If you like it, you can download Cultural Diversion from my channel.

Mark Qvist reshared this.
At times one of the adolescent girls or boys who go to see the child does not go home to weep or rage, does not, in fact, go home at all. Sometimes also a man or woman much older falls silent for a day or two, and then leaves home. These people go out into the street, and walk down the street alone. They keep walking, and walk straight out of the city of Omelas, through the beautiful gates. They keep walking across the farmlands of Omelas. Each one goes alone, youth or girl man or woman. Night falls; the traveler must pass down village streets, between the houses with yellow-lit windows, and on out into the darkness of the fields. Each alone, they go west or north, towards the mountains. They go on. They leave Omelas, they walk ahead into the darkness, and they do not come back. The place they go towards is a place even less imaginable to most of us than the city of happiness. I cannot describe it at all. It is possible that it does not exist. But they seem to know where they are going, the ones who walk away from Omelas.
- Ursula K. Le Guin, The Ones Who Walk Away From Omelas (1973)
After reading this, you might feel like you owe it to yourself to read the whole story. If so, you would be right. It is only four pages long, but it will probably have a larger impact than anything else you will come across today. You can easily find a PDF version by searching online.
The name Omelas is a semi-anagram of שָׁלֵם, the biblical Salem, and shares the common root with שָׁלוֹם (shalom), or simply "peace".

First #LXMF message delivered to a standalone ESP32-based device over a #Reticulum link! This was just posted by stumpigit over on the RNS dev forum, who's been working on getting the microReticulum library up to date with full support for LXMF messaging.

Very cool to see this taking shape. Native LXMF messengers for small, embedded systems and micro-controllers are a step closer.
reshared this
Encrypted & Decentralized Telephony Over Reticulum
Wouldn't it be nice if you could have a real telephone, that wasn't wiretapped by default?
Encrypted, decentralized and truly peer-to-peer voice calls and telephony over Reticulum is now a reality with the newly released LXST framework. Because it uses Reticulum for data transport, LXST voice calls require no intermediary servers or accounts anywhere. Anyone with an LXST-enabled device or software client can call anyone else - as long as there is a network connection between the devices.
Using the efficient hybrid mesh routing of Reticulum, this also means that your calls aren't routed anywhere they shouldn't be. If you call an endpoint in the same building, the telephones connect directly, and not over somebody elses VoIP server in another country.

These two prototypes are fully functional telephones, that can dial to and receive calls from any other LXST endpoint. It takes about 20 minutes to assemble one, and it's built from completely standard and readily available components, obtainable from common electronics vendors.
Initial client support is already implement in the Sideband application for desktop, the command line application rnphone, and of course the physical telephone implementation.
Like other Reticulum-based protocols, authentication and encryption is handled by the self-sovereign identity layer in Reticulum. This means that you truly own your addresses, and that you can move around to anywhere in the network (or another network altogether) and still be reachable for anyone else. If you have an LXST "number", nobody can take it away from you, and there is no phone service provider to pay for the privilege of keeping it.
The system provides high-quality, real-time full-duplex voice calls between endpoints, and uses only open source software components. This includes the voice codecs, which can real-time switch between OPUS (for high quality) and Codec2 (for ultra low bandwidth) without any frame loss.
But LXST was not only designed for telephony and voice calls. In fact, it is a general purpose secure signal transport framework, that allows sending any type of analogue or digital signal over Reticulum networks, either efficiently encoded or completely uncompressed. The protocol currently supports transporting up to 32 simultaneous signal carriers with up to 128-bit floating point precision in a single stream.
It also supports transmitting digital signalling and control data in-band with the carried signal frames. This allows creating almost any kind of real-time application.
At this early stage of development, the framework includes ready-to-use primitives for telephony, signal input, output and mixing, and network transport. Future development will focus on even more primitives such as:
- Real-time distributed radio communications
- Decentralized 2-way radio systems, similar to (but more flexible than) trunked systems such as DMR and P.25
- Media broadcasting for information content such as podcasts and digital broadcast radio that anyone can set up and use
- And many more useful and interesting applications
If you want to dive deeper into this, there is more information available on the LXST source repository and in discussion threads. It's still very early days for LXST, but if you're interested in this kind of thing, it might be a good time to jump in.
#reticulum #lxst #sideband #privacy #security #voip #opensource
GitHub - markqvist/Sideband: LXMF client for Android, Linux and macOS allowing you to communicate with people or LXMF-compatible systems over Reticulum networks using LoRa, Packet Radio, WiFi, I2P, or anything else Reticulum supports.
LXMF client for Android, Linux and macOS allowing you to communicate with people or LXMF-compatible systems over Reticulum networks using LoRa, Packet Radio, WiFi, I2P, or anything else Reticulum s...GitHub
Mark Qvist likes this.
reshared this
I love a good caRNode build, and this is a great vehicle-based #Reticulum #RNode build solution by @adingbatponder!





that uses the Pi's #wifi #accesspoint #ap to allow the GUI of #MeshChat to be used on a #smartphone to access the #mesh and #message and send & receive #images #photos on the move using #Reticulum
loramesh.org/subpages/piboxnod…
( loramesh.org )
#rnode #reticulum #meshchat #reticulummeshchat




Mark Qvist likes this.
Mark Qvist reshared this.




loramesh.org/subpages/piboxnod…
Battery USB-A socket -to- USB-A male plug of USB-A to USB-C male cable --to -- USB-C female of right-angle USB-C female to USB-A micro male adapter --to-- USB-A micro Pi power input socket.

My talk from the latest edition of the Chaos Communication Congress:
Reticulum: Unstoppable Networks for the People
While there's quite a bit of technical details in this one, I also go into some of the underlying reasons behind why we really need something like Reticulum, ideally yesterday.
Please feel absolutely free to download, share, re-post and upload this video wherever you find it relevant!
Going Fast And Slow
A post about where we are, and where we're going, in terms of #Reticulum performance and scalability, and some new experimental features.

Experimental Performance Features
In the latest commits to master (version 0.9.3) of RNS, there's a few interesting (and pretty experimental) features that I think some people might want to play around with already, even though it hasn't been released yet.
First of all, a long-standing TODO has been implemented in AutoInterface, which will now sub-interface each discovered Ethernet/WiFi peer for much better performance and path discovery. AutoInterface now also supports dynamic link MTU discovery. These updates improve performance significantly.
Most "experimentally", and perhaps most interestingly, RNS now includes an optional shim for on-demand transpilation of the entire RNS implementation to C, and then compiling that to machine-local object code at run-time. If requested, this happens dynamically at daemon initialisation via Cython (and only once, of course, if no locally compiled version exists already).
The on-demand compilation step, by itself, provides an instant performance increase of around 2x in the Reticulum transport core, cutting per-packet processing time approximately in half, due to the much decreased need for context switches between the Python VM and C-based backend. Notably, this is without any of the many potential optimisations added yet, such as static typing of variables in the transport core, object property slotting, logic vectorisation and so on.
These optimisations, together with link MTU discovery now pushes the Reticulum transport core packet processing above 1.4 gigabits per second on my (relatively modest) test hardware, while still running on a single CPU core.
Faster Snake, Faster
I've never really expanded much on how I envision the path to truly massive scalability for Reticulum before, and understandably most of the community has been focusing efforts in this regard on the tried-and-true approach of developing parallel implementations of Reticulum in compiled languages such as C, Rust or Go. That approach is something I very much support and value, and even a necessary one for wider availability and adoption, so please keep up the good work! But, it is not the area I will be focusing my own efforts on, and there's some interesting, but non-obvious reasons for that, so it's probably time to expand a bit on that.
One of the most critical components in the continued evolution of Reticulum right now, is keeping the reference implementation readable, understandable, accessible and auditable. Without those qualities present, creating alternative implementations - and systems on top of Reticulum - are just too tall an order to expect anyone to care about. At the same time, Reticulum targets very demanding requirements, both in terms of security, privacy and performance (both in the context of very fast links and very slow links). Actually resolving those requirements into a real, functional system is bizarrely complex, to say the least, and honestly I do occasionally wonder how I even got this far.
From the outside, it's understandably difficult to appreciate just how much design, testing, re-evaluation, validation and implementation work it has taken to get to the point we're at now. It's taken me ten years, and let's just say that it truly has been a complex journey. For solving tasks like this, a high-level language like Python is an absolutely excellent tool, and had I started out in C (even though that is my personal "favourite language"), I don't think I'd have succeeded.
Scaling, Massively
Before discussing any further, I should clarify what massive scalability actually entails in regards to Reticulum. The current implementation is capable of handling throughputs in excess of 1 Gbps, which is definitely "good enough" for the foreseeable future. But down the line, and in the relatively near future, I think we need to start moving the target to transport capabilities of 100+ Gbps and network depths of millions (or even billions) of active endpoints.
There's a common misconception that Python is "slow", whatever is meant by that. From a more nuanced perspective, that assumption is incorrect. What can cause significant performance penalties in Python are the context switches between the Python byte-code VM and native machine code. But as I've already hinted at, those can be eliminated almost entirely by using the Python source code as a blueprint for deterministically generating machine-code, that run at native speeds. I'd estimate that simply implementing static typing, property slotting and locking the memory structures for various lookup tables will provide a further 30-50x increase in performance.
With the recent release of Python 3.13, we're also finally starting to be see the end of the notorious Global Interpreter Lock, allowing us true multi-core concurrency, and this along with the new Python JIT will speed up things even further.
But going beyond that, we're going to start needing to get a little creative. It's well-known that the TCP/IP stack is fast, but one of the primary reasons that this holds true in practical reality is a little less well-known.
On commercially available IP routers, be that consumer products or ISP-scale hardware, almost all of the packet processing doesn't actually occur on the CPU, but is hardware accelerated on custom ASICs, embedded in the router chipset. If you've ever tried bonding IP interfaces or inserting software based VPNs in your routing path on systems that provide no hardware acceleration for those operations, you will have seen your previous line-rates drop to significantly less impressive numbers.
There's not any real possibility of hardware vendors starting to design, fab and ship Reticulum-specific acceleration ASICs any time soon, so we can't rely on that approach. What we can rely on instead, is another type of general-purpose parallelisation solution, that has seen massive improvements in the recent years, and which is now more or less ubiquitous in all compute devices, the GPU. Even mobile chipsets and embedded SBCs include capable GPUs with quite ample memory and shader core counts.
By leveraging existing, general-purpose acceleration frameworks (such as OpenCL or Vulkan Compute), a truly general-purpose Reticulum packet-processing accelerator can be designed and deployed on more or less any existing system, essentially for free - at least in the sense that no new hardware has to be invented.
If active path tables and other transport-essential data structures are shipped off to GPU memory, and the internal states of the Reticulum transport core is made completely vectorisable, packet processing can truly be massively parallelised. The transport logic was already designed with such vectorisation in mind, but of course it will take some work to get there.
The beauty of this approach is that it will still work on any type of CPU as well, even if no acceleration hardware is present on the system. This allows for a single implementation that will dynamically adapt to whatever resources are available on the system, from a single-core SBC, to an accelerated core transport node capable of handling tens of millions of packets per second.
While all of this is immensely interesting, and something I'd love to sink myself into right now, realistically it's still something a ways off into the future, since there's plenty of other important work to do first. Still, I thought it would be good to share some of thoughts that form the basis of the current optimisation work, and where it is ultimately going.
This post is also available on unsigned.io
like this
reshared this
Mark Qvist
in reply to Mark Qvist • •